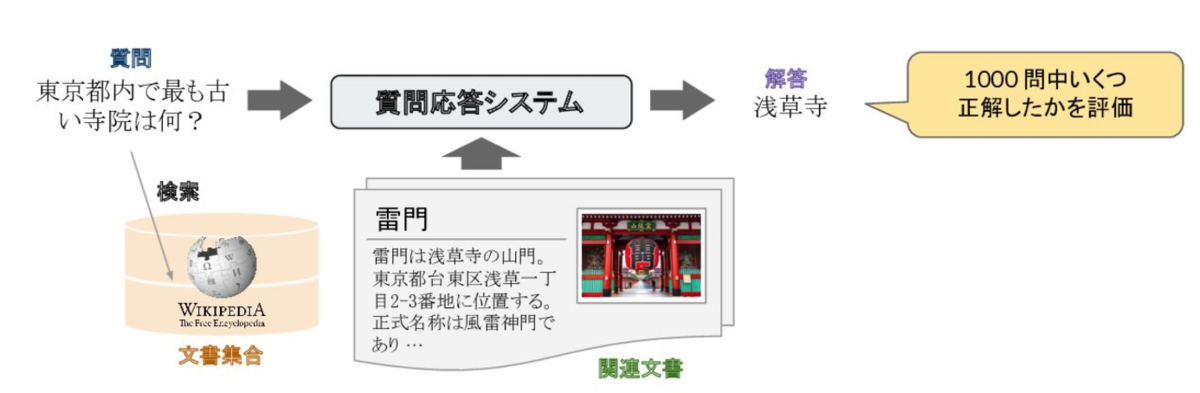
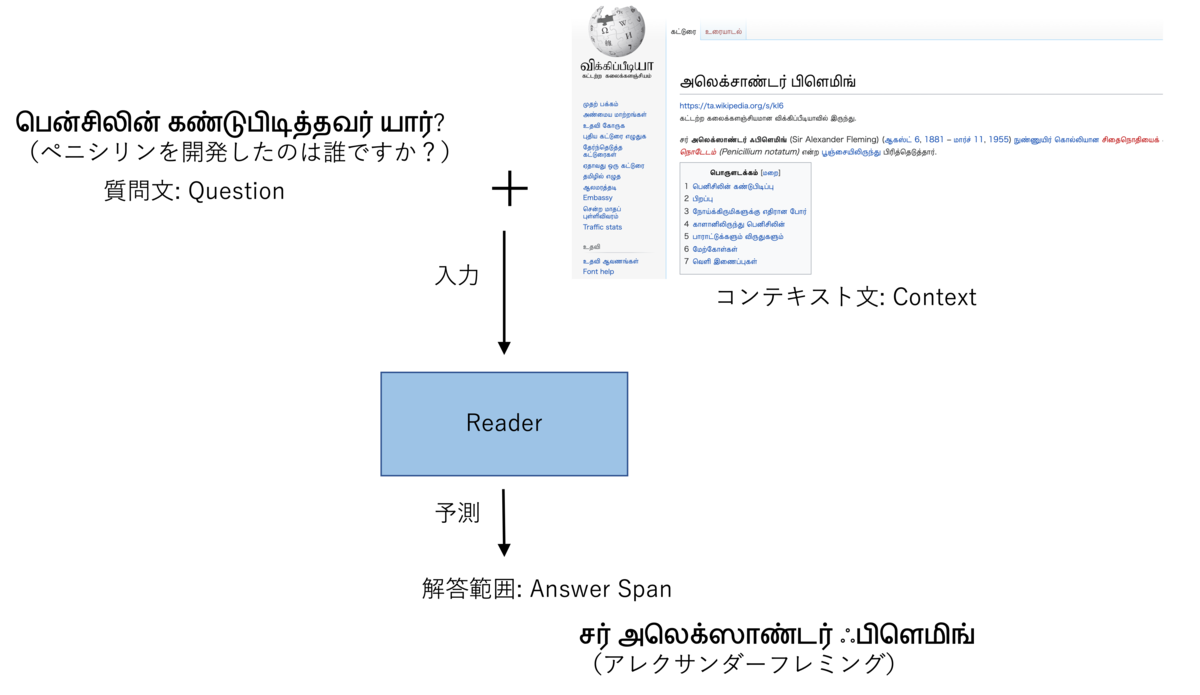
こんにちは。エクサウィザーズで画像ギルドに所属し、機械学習エンジニアをしている小島です。今年の3月からこちらにジョインいたしました。
この記事では、弊チームで取り組んいるテーマ「Zero-shot Learning」について、歴史的な背景を振り返りつつ、簡単な実装を紹介します。今研究でホットな研究テーマの一つである「クロスモーダルモデル」を身近に感じていただければ幸いです。
Zero-shot Learningとは
「Zero-shot Learningとは何か」というのは、実は曖昧なテーマです。「これがZero-shotだ」という定義が論文によって異なるためです。わかりやすい理解の仕方としては、Many-Shot Learning、One/Few-shot Learningから天下り的に考えていくことでしょう。

画像系の機械学習の問題は、大きく分けて、タスクの軸とデータ数の軸の2軸で考えられます。
タスクの軸については、分類問題(Classification)、物体検出(Object Detection)、セマンティック/インスタンスセグメンテーション(Instance/Semantic Segmentation)を最も基本的な3つのタスクとして挙げています。タスクの軸はこれ以外にもいろいろあるので、この3つが正解というわけではありません。
本題はデータ数の軸で、ここでは「タスク固有の訓練データ」を意味します。例えば、「犬か猫か」の画像分類モデルを訓練したい場合、犬の画像を数百枚、猫の画像を数百枚持ってきて、ImageNetで訓練されたモデルをfine-tuningするのが一般的なやり方でしょう。この場合、タスク固有の訓練データは「数百枚×クラス数(犬or猫=2)」必要となり、データ数の軸では「Many-shot」となります。

では、Few/One-shotとは何でしょうか。One-shotとは文字通り、タスク固有の訓練データが1つ、Fewなら数枚か~少し多い程度でしょうか。Few/One-Shotの典型例は顔認証です。例えば、1人あたり数百枚の顔写真を入れ、顔認証をMany-shotの問題として訓練・運用するのは現実的でありません。データが取れないという問題もありますし、認証対象に1人追加されるとクラス数が変わるため、モデル全体を訓練し直さないといけないからです。この図は[1]の論文からのものです。

One-shot Learningでは、「クラスが同一かどうかを学習している」点に注意してください。Many-shotでは、犬や猫といった特定のクラスに属するかを学習していました。ここで大事なのが、学習やタスクの設定を工夫すれば、タスク固有の訓練データは減らせるという点です。ここの改良はZero-shotでも続けられています。
Zero-shot黎明期
ディープラーニングのZero-shotの論文に行く前に、Zero-shotの発端となりうる論文を2つ紹介します。
Zero-shot Learning
1つ目は、Palatucci et al.(2009)によって書かれた論文です[2]。AlexNet[3]が2012年に発表されたので、これはディープラーニングのブームが来る前の論文です。論文のタイトルにも「Zero-shot Learning」とついていますが、本文中にZero-shot Learningについて問題提起しています(※翻訳はDeepLで作成しています)。
Given a semantic encoding of a large set of concept classes, can we build a classifier to recognize classes that were omitted from the training set?
大規模な概念クラス集合の意味論的符号化が与えられたとき、学習集合から漏れてしまったクラスを認識する分類器を構築できるか?
また、アブストラクトでは、Zero-shot Learningを以下のように定義しています。
We consider the problem of zero-shot learning, where the goal is to learn a classifier
that must predict novel values of
that were omitted from the training set.
学習セットから漏れてしまった新しい
訓練データにはないクラスを認識することがポイントで、この観点は現在のZero-Shot Learningでも根底にある思想の1つです。
なお、この論文の著者にはジェフリー・ヒントンとトム・ミッチェルがいます。ジェフリー・ヒントンはディープラーニング界のゴッドファーザーの1人として非常に有名な研究者です。トム・ミッチェルの「機械学習の定義」は非常によく引用されるので、どこかで見た方もいらっしゃるのではないでしょうか。彼の著書[4]からです
A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.
コンピュータ・プログラムが、あるタスクのクラスTと性能指標Pに関して、経験Eから学習すると言われるのは、Tのタスクにおける性能が、Pによって測定されるように、経験Eとともに向上する場合である。
Zero-data Learning
2つ目はLarochelle et al.(2008)らによって書かれた、「Zero-data Learning of New Tasks」という論文[5]です。「Zero-data Learning」と「Zero-shot Learning」紛らわしいですね。図はZero-data Learningの論文からです。

「Zero-data Learning」は以下のように定義されています。
We introduce the problem of zero-data learning, where a model must generalize to classes or tasks for which no training data are available and only a description of the classes or tasks are provided.
ゼロデータ学習とは、学習データがなく、クラスやタスクの説明のみが提供されているクラスやタスクに対してモデルを汎化しなければならない問題である。
Zero-data Learningの特徴として「学習データがない」という点が明確に記載されています。また、クラスやタスクの説明のみが提供されているということも興味深い。実はこのZero-data Learningの説明こそ、後で紹介するCLIPのやっていることと一致するという点も、頭の片隅に入れておきたい点です。
論文の図を見ると、左側は手書き数字の「1,2,3」のみ訓練データとして与え、「A, B」を推論するケースで、これは完全に学習データがないケースです。真ん中はマルチタスク学習で、欠損値補完のイメージでしょうか。いずれにしても「学習データがないクラスや組み合わせに対して推論する」という点がポイントです。
冒頭で、「現在のZero-shot LearningはMany-shotやFew/One-shot Learningから天下り的に考えると、タスク固有の訓練データがない学習方法だ」ということを述べました。まさにこれが、Zero-data Learningの考え方と重なるわけです。
すなわち、現在のディープラーニングでZero-shot Learningと呼ばれているものは、厳密にいえば、Palatucci el al. (2009)のZero-shot Learningと、Larochelle et al. (2008)のZero-data Learningの少なくとも2つの側面があると言えます。現状では、各論文の著者が「これがZero-shotだ」と言っているので、源流の論文を明確に意識する機会はほとんどありません。しかし、10年以上前の論文の思想が、現在も普遍的に生きていることには驚かされます。
Larochelle et al. (2008)の著者には、同じくディープラーニングのゴッドファーザーと呼ばれるヨシュア・ベンジオが含まれています。AI界の伝説の存在が10年以上前に揃ってこのトピックに取り組んだことから考えると、Zero-shotはそれだけに魅力的な問題なのでしょう。
時代はテキストと画像のクロスモーダルへ
クロスモーダルのアプローチ
Zero-shotを「テキスト」と「画像」のクロスモーダルの問題として捉えたのが、Socher et al.(2013)[6]です。これまでのZero-shot LearningもZero-data Learningも、教師データがあるのを前提にしていました。本論文の大きな違いは、あらかじめ用意された大規模なコーパスから、ラベルのテキストの埋め込み量と外れ値検出を組み合わせて、未知の画像のクラスを推定している点です。

イメージとしては、「truck」と「cat」が未知のクラスだとします。猫の画像が与えられた場合、まず既知のクラスに対して「未知である」という外れ値検出します。そして、テキストの埋め込み量を使い、近傍の「猫」である推定します。ポイントは、大規模なコーパスを使っているため、クラスのラベルとしては、トラックも猫も既知であることです。
なお、この論文の著者には、同じく機械学習界の重鎮であるアンドリュー・ンがいます。私も含め、彼のCourseraの講義にはお世話になった方が多いのではないでしょうか。
DeViSE
Socher et al.(2013)[6]をもう少しこなれた形にしたのが、DeViSE[7]です。DeViSEでは、外れ値検出を使わず、画像と単語の類似度を直接学習していきます。後で紹介するCLIPにかなり近いモデルです。

クロスモーダルのアプローチを使ったのはこの論文が初ではありませんが、要旨には「ラベル付き画像だけでは学習データの取得に限界があるから、テキストデータを活用して精度を高めよう」という意図が書かれています。私がZero-shotを調べたときに「なぜ学習データがないタスクに対して、text-supervisedのアプローチがデファクトスタンダードとして扱われているのか」という点が理解できませんでした。おそらくDeViSEのあたりから、このような方向性が確立されてきたのかな考えられます。
DeViSEの論文は、Googleのチームによって書かれたものですが、著者にはジェフ・ディーンがいます。Zero-shotはどれだけ界隈のレジェンドを惹き付けるのでしょうか。
Visual N-Grams
Visual N-Grams[8]は、現在のCLIPのように、インターネットからダウンロードした膨大な画像-テキストの組み合わせに注目した論文です。

自然言語処理では古くからN-Gramモデルが使われていますが、この考え方を画像に転用したものです。例えば、港にあるクレーンを1つとっても、人間は「navy yard」や「サンディエゴの港」のような多面的な認識をします。Visual N-GramsでもZero-shotへの言及はありますが、Visual N-Gramsの論点が現在のZero-shotを俯瞰するには有用だと思います。要旨からです。
Real-world image recognition systems need to recognize tens of thousands of classes that constitute a plethora of visual concepts. The traditional approach of annotating thousands of images per class for training is infeasible in such a scenario, prompting the use of webly supervised data. This paper explores the training of image-recognition systems on large numbers of images and associated user comments, without using manually labeled images.
実世界の画像認識システムでは、膨大な数の視覚的概念を構成する何万ものクラスを認識する必要があります。このようなシナリオでは、クラスごとに数千枚の画像にアノテーションを付けて学習する従来のアプローチは現実的ではなく、Webから学習したデータの利用が必要である。本論文では、人手でラベル付けした画像を用いずに、大量の画像と関連するユーザコメントから画像認識システムを学習する方法を検討する。
ポイントは2点あります。
- 実世界の画像認識を考えると、(人間のような)何万ものクラスを多面的に認識したい。従来のMany-shotのアプローチはこれに向かない
- アノテーションは、人がつけるのではなく、Webに付随しているデータ(コメント)から直接利用するべき
つまり、従来のMany-shotの問題設定としての限界、アノテーションを人間がしたくないことの2点が、この背景となる思想です。これを知ることで、現在のZero-shotの流れが理解しやすくなります。
Contrastive Learning
最初は次元削減から
今まで、Zero-shot Learning、クロスモーダルに関する論文をいくつか紹介してきましたが、CLIPを理解するためには「Contrastive Learning」について知っておく必要があります。そもそもCLとはどのようにして生まれたのでしょうか?
Contrastive Learningの原案は、これもディープラーニングがブームになる前から生まれていました。Hadsell et al.(2006)[9]は、「spring system」と呼ばれる次元削減のための学習システムを構築しました。これはもともと、高次元のデータを低次元の多様体にマッピングする次元削減の問題として提案されました。図はこちらの論文からです。

黒い丸は類似サンプル、白は似ていないサンプルです。このように似ているサンプル同士を近づけて、似ていないサンプル同士を離すという、バネのようなシステムであったから「spring system」と呼ばれました。spring systemという呼び方は現在ほとんどされませんが、考え方自体は現在のContrastive Learningと同じです。
なお、この著者にはヤン・ルカンがいます。Zero-shot Learningを追っているだけで、「ディープラーニングのゴッドファーザー」と呼ばれているチューリング賞受賞の3人:ヤン・ルカン、ヨシュア・ベンジオ、ジェフリー・ヒントンの論文をコンプリートできます。
SimCLR
ディープラーニングにおけるContrastive Learningの大きなブレイクスルーになったのがSimCLR[10]です。

2020年の論文で、spring boxからいきなり時代を飛び越えましたが、「サンプル間の類似度を学習し、類似したものを近づけようとする」という大枠は変わっていません。はData Augmentationで、同一のデータ
をData Augmentationして、異なるサンプル
を得ます。これを同じニューラルネットワークに通して、類似度を学習します。SimCLRはクロスモーダルではなく、画像で完結するためこのようなAugmentationを入れています。
SimCLRは、ディープラーニングの問題としてシンプルな枠組みで実現し、教師なし学習でも教師あり学習に迫る精度を達成したことから、大きな注目を集めました。SimCLRのような枠組みは自己教師あり学習(Self-supervised learning)とも呼ばれます。教師ありとはいうものの、自分自身を教師として使うため、従来の教師あり学習のように人間が作ったラベルは必要ありません。これは、先程紹介したクロスモーダルなモデルと発想が似ています。
SimCLRの著者には、またヨシュア・ベンジオがいます。先程紹介したZero-data Learningから14年越しです。これだけ長い期間、インパクトのある研究を出し続けられるのは本当に驚かされます。
なお、この記事を読んでいる方には「Contrastive Learningと、One-shot Learningの文脈で語られることの多いMetric Learningは何が違うのか?」という疑問も抱いた方もいるかもしれません。私もこの疑問を持っていたのですが、最近ではContrastive LearningにMetric Learningの要素を加えた研究[11]もあり、両者の境界が曖昧になっています。厳密には違いがあるのかもしれませんが、方言の違いぐらいの認識で良いと思います。
CLIP誕生
クロスモーダルなZero-shot Learning
これまで長い期間をかけて、
- Zero-shot Learning
- 画像と文章のクロスモーダル
- Contrastive Learning
の3つを紹介しました。これらはすべて「CLIP[12]」を説明するためのパーツです。いよいよCLIPを見ていきましょう。
CLIPはOpenAIによって2021年に発表された激強論文です。Zero-shotかつクロスモーダルで、従来のImageNetで訓練済みのMany-shotのモデルよりも頑強性が高いことが大きく注目されています。以下の図はCLIPの論文からですが、目にした方も多いのではないでしょうか。

CLIPもContrastive Learningをしています。SimCLRでは、1つの画像にData Augmentationを適用して2種類の画像を作り、その類似度を最大化していました。CLIPでは、これが画像とテキストのクロスモーダルなので、1枚の画像とそれに対応するキャプションの類似度を最大化するようなContrastive Learningになります。画像のキャプションとはどういうものかというと、次のようなものです。これはOpen Images Dataset V6[13]のサンプルで、元画像の作者は[14](CC BY 2.0)です。

「Fractal Cauliflower」というのがキャプションです。インターネット上の画像(例:Flicker、Instagram)には、キャプションが付属していることが多いので、それを活用します。この例では、キャプションを通じて「幾何学的」と「カリフラワー」の2つの概念を学習できます。
ただし、テキストと画像の特徴量は同じネットワークでは計算できないため、それぞれ別のモデル(例:Transformer、Vision Transformer)を使います。例えば、バッチサイズを、特徴量の次元を
とすると、画像とテキストネットワークの出力特徴量は、それぞれ
次元で表されます。これらの行列積を取り出し、
というコサイン類似度の行列を作り、対角成分を正例、それ以外を負例としてContrastive LearningするのがCLIPです。

この図も論文からの引用です。ポイントは、コサイン類似度の実装をL2-Normalizeで行われていることで、ベクトルに対するコサイン(類似度)というのは、
で表されます。これは高校数学の教科書にも載っている公式ですが、右辺はL2-Normalizeそのものです。行列に拡張したのが上図のコードです。高校数学でおなじみの公式が、最先端の研究のキー技術になっているのは、学校で教えて欲しいぐらいです(機械学習で高校数学がいるよ、と言われるのはこういう理由です)。
ロジットの計算の部分で、さらっと温度付きの計算して、さらに学習パラメーターとするという面白いことをやっているのですが、それはおいておきましょう。
プロンプトエンジニアリング
CLIPでは、訓練時に画像の持っているキャプションを活用しましたが、推論時はどう考えているのでしょうか。推論時の画像はキャプションを持っていない場合も多いです(例:カメラから撮った画像)。CLIPではプロンプト(prompt)という、自然言語処理由来の独特な概念が出てきます。この図はOpenAIのブログ記事からです[15]

飛行機を推定するには、「a photo of a airplane / bird / bear / ...」といろいろなテキストがありますよね。このようにターゲットとなるテキストを複数提示して、最も類似度の高いテキストを選択するのが、CLIPの推論方法です。ここで「a photo of {label}」というテンプレートが、プロンプトです。プロンプトという単語は聞き慣れませんが、Windowsに出てくる「コマンドプロンプト」を連想すると馴染み深いのではないでしょうか。プロンプトを調整して精度を上げていくのがプロンプトエンジニアリングです。機械学習でおなじみの「特徴量エンジニアリング」の仲間として捉えると理解しやすいかもしれません。
CLIPでのプロンプトエンジニアリングは、この他に「A photo of a big {label}」「A photo of a small {label}」というように、複数のプロンプトを組み合わせてアンサンブルします。これが精度の改善に大きく寄与します。CLIPの論文からです。

プロンプトエンジニアリングとアンサンブルにより、ImageNetのZero-shot精度を5%、モデル計算量で4倍改善できたとのことです。ここはこの記事本来の目的ではないので、細かくは書きませんが、CLIPには「プロンプト」というクロスモーダル特有の概念が出てくるよ、ということを覚えておいてください。やっていることは単なるテンプレート構文です。
CLIPとZero-data Learnig、Visual N-Grams
今回は「CLIP」の紹介が主な目的ですが、CLIPより前の古い論文もいくつか掲載しました。その理由は、10年以上も前の古い論文で培われた思想が、CLIPでも生きていることを味わってほしかったのと、CLIPがどういった理念から作られたのかを知ってほしかったからです。私個人が純粋に興味あったからというのもあります。
さて、最初にZero-data Learningの論文を紹介しました。CLIPはZero-shot Learningでありながら、実はZero-data Learningの要素もかなり含んでいます。Zero-data Learningを再度引用してみましょう。
We introduce the problem of zero-data learning, where a model must generalize to classes or tasks for which no training data are available and only a description of the classes or tasks are provided.
ゼロデータ学習とは、学習データがなく、クラスやタスクの説明のみが提供されているクラスやタスクに対してモデルを汎化しなければならない問題である。
単に学習データがないというと誤解を招きますが、CLIPにはMany-shotのようなタスク固有の学習データがないのは事実です。ユーザーがFine-tuningしなくても、学習済みモデルに、飛行機の画像とプロンプトを与えれば、飛行機だと推論できます。「クラスとタスクの説明のみ提供されている」という点はまさにプロンプトです。
つまり、CLIPは「訓練データにはないクラスを認識する」というZero-shot Learningの文脈にありながら、Zero-data Learningをまるで伏線回収のように取り込んでいるのです。13年越しにこのような回収して、大きなブレイクスルーを導き出したのはかなり痺れるものがあります。
Visual N-Gramsは、CLIPの論文内でも比較対象として言及されるほど、強く意識していた論文です。Visual N-Gramsのポイントを再掲します。
- 実世界の画像認識を考えると、(人間のような)何万ものクラスを多面的に認識したい。従来のMany-shotのアプローチはこれに向かない
- アノテーションは、人がつけるのではなく、Webに付随しているデータ(コメント)から直接利用するべき
CLIPは、アノテーションの事情もふまえつつ、人間のような多面的かつ何万クラスの認識をしたいという考え方を受け継いでいるわけです。多面的な認識はプロンプトのラベルの単語を変えることで可能にしていますし、アノテーションはクロスモーダルなContrastive Learningによって解決しています。Visual N-Gramsの要旨で書かれたような、実世界の画像認識がCLIPの登場でより現実的になったということが言えるでしょう。
CLIPの欠点
万能のように書いたCLIPですが、実は欠点もあります。それはモデルの訓練に莫大な量のGPUとデータが必要なことです。CLIPの論文からです。
The largest ResNet model, RN50x64, took 18 days to train on 592 V100 GPUs while the largest Vision Transformer took 12 days on 256 V100 GPUs.
最大のResNetモデルであるRN50x64の学習には592台のV100 GPUで18日、最大のVision Transformerは256台のV100 GPUで12日かかりました。
ResNet50×64でV100が592×18=29.2年分も必要です。ResNet50×4に減らしても1回訓練するだけで1.8年分のGPUが必要です。CLIPのような強いモデルをスクラッチから訓練できるのが、ビックテックのような限られた存在になってしまい、技術を寡占されてしまわないかという懸念があります(訓練に億円単位がかかるモデルを自由に利用できるように公開する、仏のような心の持ち主が多数いるのを期待したいです)。
また、必要なデータ数も莫大です。後で説明する後続研究のSLIP[16]によれば、CLIPは4億枚の画像-テキストのデータを使用しており、これを1500万枚に減らしたところViT-BでImageNetのZero-shot精度が37.6%になったと報告されています[17]。300万枚では、同じモデルで17.1%まで落ちてしまいました。Zero-shotの精度を教師ありImageNet並に上げたければ、億単位の膨大なデータを使った訓練が必要という身も蓋もない話になります。
SLIPの論文によれば、ViT-B/16でCLIPを再実装するために、1500万枚に限定しても64台のV100で22.3時間(59.4日分)だったことが記されています。V100を2ヶ月使ってImageNetが40%行けばいい、というのはなかなか考えさせられるものがあります。
CLIPの先にあるもの
激強の論文として紹介したCLIPですが、訓練済みCLIPを使った研究が最近(2022年)とても活発です。CLIPのその後の論文をいくつか紹介していきましょう。
CLIPの改良
まずはダイレクトにCLIPの学習をより効率的にする方法です。1つ目はUC BerkeleyとFacebook AIのチームが2021年に発表したSLIP[16]で、図は論文からです。これはCLIPの画像側に自己教師あり学習を組み合わせ、先程紹介したSimCLRを画像側に追加したものです。CLIPよりも精度が高くなります。

2つ目はICLR 2022で発表されたDeCLIP[18]です。(1)モダリティ内、(2)複数のビューを通じたモダリティ間、(3)類似ペアから最近傍、それぞれの自己教師あり学習します。これにより、CLIPよりも7.1倍少ないデータ数で同じ精度を達成できています。

生成モデルへの応用
訓練済みCLIPと生成モデルは相性が良く、AnyFace[19]ではテキストを使って、ソースの顔写真から自在に合成できる手法です。

DALL・E 2[20][21]は、「馬に乗る宇宙飛行士」のようにテキストを入力すると画像を生成するモデルで、非常に精緻な画像が生成されることで話題になりました。この実装には訓練済みCLIPと拡散モデルが使われています。画像はOpenAIのサイトからです。

生成モデル以外にもCLIPの応用は多数あるのですが、これを紹介するときりがなくなるので割愛します。CLIPの活用がまさに研究の最先端で行われています。
SLIP(CLIPの後続研究)を動かしてみる
記事の締めくくりとして、Zero-shotのモデルを実際に動かしてみましょう。CLIPの推論は有用な記事が多数あるので、ここでは後続研究のSLIP[16]を動かします。CLIPのように使い勝手の良いAPIは整備されていませんが、公式のコード[17]をいじることで比較的簡単に実装できます。
ダウンロード
まずはSLIPの公式リポジトリからソースコードをダウンロードしてきます。PyTorchとtimmが別途必要です。
同じリポジトリから、訓練済みモデル(チェックポイント)をダウンロードします。いくつかモデルがありますが、ここでは「ViT-Base / SLIP / 100Epochs」(0-shot 45.0%)をダウンロードします。「Weights」のurlからダウンロードできます。2GB近いファイルなので、容量に気をつけてください。
先程クローンしたリポジトリの直下に「weights」フォルダを作り、そこに保存します。
チェックポイントの軽量化
ダウンロードしたチェックポイントは、推論に不要なパラメーターも含んでいるので、軽量化します。これにより、1.9GB→651MBに軽量化されます。元のチェックポイントは削除して構いません。
import torch from collections import OrderedDict from tokenizer import SimpleTokenizer import models from torchvision import transforms from PIL import Image import numpy as np def strip_checkpoint(ckpt_path): ckpt = torch.load(ckpt_path, map_location='cpu') state_dict = OrderedDict() for k, v in ckpt['state_dict'].items(): state_dict[k.replace('module.', '')] = v old_args = ckpt['args'] print("=> creating model: {}".format(old_args.model)) model = getattr(models, old_args.model)(rand_embed=False, ssl_mlp_dim=old_args.ssl_mlp_dim, ssl_emb_dim=old_args.ssl_emb_dim) model.cpu() model.load_state_dict(state_dict, strict=True) print("=> loaded resume checkpoint (epoch {})".format(ckpt['epoch'])) torch.save(model, "weights/"+old_args.model) strip_checkpoint("weights/slip_base_100ep.pt")
推論関数の作成
SLIPにはCLIPのように簡単に利用できる推論APIがないので、それっぽいものを作ります。公式コードをアレンジしたものです。
def load(model_name, device): model = torch.load("weights/"+model_name).to(device) image_preprocess = transforms.Compose([ transforms.Resize(224), transforms.CenterCrop(224), lambda x: x.convert('RGB'), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) ]) tokenizer = SimpleTokenizer() return model, image_preprocess, tokenizer def inference(img_path, templates, classes, device="cuda:0"): model, image_process, tokenizer = load( "SLIP_VITB16", device) image = image_process(Image.open(img_path)).unsqueeze(0).to(device) text_features = [] with torch.no_grad(): # 言語特徴量 for label in classes: texts = [t.format(label) for t in templates] texts = tokenizer(texts).to(device) texts = texts.view(-1, 77).contiguous() class_embeddings = model.encode_text(texts) class_embeddings = class_embeddings / class_embeddings.norm(dim=-1, keepdim=True) class_embeddings = class_embeddings.mean(dim=0) class_embeddings = class_embeddings / class_embeddings.norm(dim=-1, keepdim=True) text_features.append(class_embeddings) text_features = torch.stack(text_features, dim=0) # (n_classes, 512) # 画像特徴量 image_features = model.encode_image(image) image_features = image_features / image_features.norm(dim=-1, keepdim=True) # コサイン類似度→ロジット→確率 logits_per_image = model.logit_scale.exp() * image_features @ text_features.t() pred_prob = torch.softmax(logits_per_image, dim=-1).cpu().numpy() return pred_prob
img_pathは画像のパス、templatesはプロンプト、classesはクラス名のテキストを表します。プロンプトとクラス名を固定で複数の画像を推論したい場合は、言語特徴量やモデルをキャッシュさせるとよいでしょう。
一番いい推論を頼む
SLIPを使って画像を推論してみましょう。使用するサンプルは「そんな装備で大丈夫か?」で話題になったエルシャダイ[22]です。フリー素材として公開されている[23]ので、ありがたく利用します(画像クレジットはこちらで付与したものです)。

ではイーノックが何を着ているのかSLIPで判定してみましょう。ちゃんと装備をつけていると判定できるでしょうか?
# プロンプト templates = { "a picture of a {}.", "a {} in a video game.", "a {} in an animation.", "a {} in a movie." } classes = ["man wearing uniform", "man wearing swimsuits", "man wearing armor", "naked man"] result = inference("e3_luciferpv_1080p_free/02/e3_luciferpv_1080068.jpg", templates, classes) print(classes) print(np.round(result, 3))
プロンプトは4個与えてアンサンブルしています。クラスの候補としては、
- man wearing uniform(制服を着ている)
- man wearing swimsuits(水着を着ている)
- man wearing armor(鎧を着ている)
- naked man(裸)
の4つを与えました。結果は以下の通りです。
['man wearing uniform', 'man wearing swimsuits', 'man wearing armor', 'naked man'] [[0.121 0.001 0.877 0. ]]
87.7%の確率で鎧を着ているとなりました。「大丈夫か?」と心配されるような装備でも無事に鎧と認識できました。
Zero-shotの面白いところは、追加の訓練もモデルを変更しなくても、問題の枠組みを変えられるところです。先程は「何を着ているか?」の分類でしたが、今度は「どんな行動しているか?」の分類にしてみます。

イーノックがキックしているシーンです。この写真だけでキックと認識できるでしょうか? 選択肢を次のように与えて同様に推論してみます。
- man shooting(射撃している)
- man kicking(キックしている)
- man sleeping(寝ている)
- man eating(食べている)
['man shooting', 'man kicking', 'man sleeping', 'man eating'] [[0.16 0.818 0.018 0.004]]
81.8%で蹴りと判定できました。shootingは攻撃モーションから、近いと判断されたのかもしれません、行動認識と組み合わせると面白そうですね。
まとめ
本記事では、クロスモーダルでZero-shot LearningのブレイクスルーであるCLIPが、過去の論文からどういう思想のもとで生まれたのかを俯瞰し、Zero-shotのモデルとしてSLIPの使い方を紹介しました。ディープラーニングのゴッドファーザー達が過去に生み出したアイディアが脈々と受け継がれ、CLIPによって一気に開花し、まさに今Zero-shotかつクロスモーダルなモデルが、社会実装へと向かいつつあります。このダイナミズムをぜひ一緒に体感しましょう。
引用
- Koch, Gregory, Richard Zemel, and Ruslan Salakhutdinov. "Siamese neural networks for one-shot image recognition." ICML deep learning workshop. Vol. 2. 2015.
- Palatucci, Mark, et al. "Zero-shot learning with semantic output codes." Advances in neural information processing systems 22 (2009).
- Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton. "Imagenet classification with deep convolutional neural networks." Advances in neural information processing systems 25 (2012).
- Tom Mitchell. "Machine Learning." McGraw Hill. 1997.
- Larochelle, Hugo, Dumitru Erhan, and Yoshua Bengio. "Zero-data learning of new tasks." AAAI. Vol. 1. No. 2. 2008.
- Socher, Richard, et al. "Zero-shot learning through cross-modal transfer." Advances in neural information processing systems 26 (2013).
- Frome, Andrea, et al. "Devise: A deep visual-semantic embedding model." Advances in neural information processing systems 26 (2013).
- Li, Ang, et al. "Learning visual n-grams from web data." Proceedings of the IEEE International Conference on Computer Vision. 2017.
- Hadsell, Raia, Sumit Chopra, and Yann LeCun. "Dimensionality reduction by learning an invariant mapping." 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR'06). Vol. 2. IEEE, 2006.
- Chen, Ting, et al. "A simple framework for contrastive learning of visual representations." International conference on machine learning. PMLR, 2020.
- Chen, Shuo, et al. "Large-margin contrastive learning with distance polarization regularizer." International Conference on Machine Learning. PMLR, 2021.
- Radford, Alec, et al. "Learning transferable visual models from natural language supervision." International Conference on Machine Learning. PMLR, 2021.
- https://storage.googleapis.com/openimages/web/index.html
- https://www.flickr.com/people/tristanf/
- https://openai.com/blog/clip/
- Mu, Norman, et al. "SLIP: Self-supervision meets Language-Image Pre-training." arXiv preprint arXiv:2112.12750 (2021).
- https://github.com/facebookresearch/SLIP
- Li, Yangguang, et al. "Supervision exists everywhere: A data efficient contrastive language-image pre-training paradigm." arXiv preprint arXiv:2110.05208 (2021).
- Sun, Jianxin, et al. "AnyFace: Free-style Text-to-Face Synthesis and Manipulation." arXiv preprint arXiv:2203.15334 (2022).
- https://openai.com/dall-e-2/
- Ramesh, Aditya, et al. "Hierarchical Text-Conditional Image Generation with CLIP Latents." arXiv preprint arXiv:2204.06125 (2022).
- http://elshaddai.jp/elshaddai_crim/index.html
- http://elshaddai.jp/elshaddai_crim/freedeta.html