こんにちは。MLエンジニアの川畑です。
今回は、以前から気になっていながらも、中々参加の一歩が踏み出せなかったKaggleについに参加したところ、幸いにも 46th / 2426チームで銀メダルを獲得しましたので、初参加を振り返りたいと思います。
なお、本記事では上位陣の解法の詳細は紹介しませんので、ご興味がある方はKaggleのコンペサイトに投稿されている解法を参照ください(https://www.kaggle.com/c/shopee-product-matching)。
前提
- 取り組んだ時間
- 本コンペに参加し始めたのはコンペ終了まで残り1ヶ月を切った頃で、基本的には業務終了後から就寝までの間で平均2時間程度、週4〜5日程度Kaggleに時間を割いていました。自分は休日にダラダラするのが好きなので、どちらかというと平日の方が取り組んでいました。また、幸いなことにコンペ開催終盤にはGWが重なったので、そのタイミングで比較的時間を費やすことができました。
- 実験環境
- 私は自前のGPUを持っていないため、Kaggle notebookとGoogle Colabのみで実験を回しました。1週間に利用できる時間や連続で利用できる時間などに制限があるため、大量の実験や時間のかかる実験を回す必要があるコンペでは、これらの無料リソースだけだとかなりしんどいのではないかと思います。また、Google Colabでは毎回データをコピーしてこないといけなかったり、1日ガッツリ利用すると使用量上限に達し、次の日に制限がかかって利用できなかったりと、少々使いづらい部分もありました。とはいえ、無料でGPUを利用できるのは非常にありがたいことです(有料のGoogle Colab Proを使えばもう少し制限は緩和されます)。
コンペ概要
本コンペは、2021/03/08~2021/05/10にShopeeという東南アジアのeコマースプラットフォームが開催したもので、商品の画像とタイトルから同一商品を検索するという課題でした。
一般に小売企業は、自社の商品が最も安いことをお客様に保証するために、さまざまな方法を用いています。中でも、他の小売店で販売されている商品と同等の価格で商品を提供する「プロダクトマッチング」という手法があります。しかし、同じ商品であっても、小売業者によって使用する画像やタイトルなどが大きく異なることもあり、同じ画像や同じタイトルで単純にマッチングさせるだけでは不十分です。そこで機械学習を使ってマッチングの精度を向上させたい、というのが本コンペのモチベーションと考えられます。実際に、Shopeeでも掲載されている何千もの商品に対して「最低価格保証」機能を提供しており、このコンペでのアプローチが活用されることが想定されます。
提供データ
学習データには34250件の商品が含まれ、テストデータには70000件程度の商品があると記載されていました。
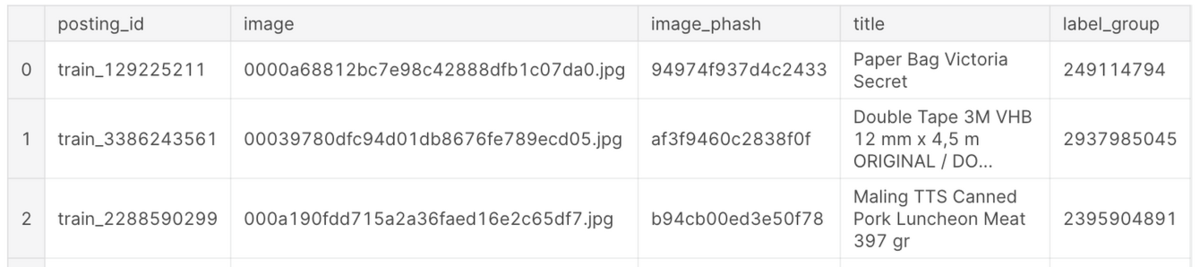
posting_id: 投稿ID(各投稿にユニークなID。商品が同じでも投稿者が違えば異なるIDになる)image: 商品画像image_phash: 商品画像のperceptual hash(これは画像を64bitのハッシュ値に変換したもので、同じ画像からは同じ値、また似た画像からは似た値が得られます。ちなみにモデルを作成する上で、この情報は使用しませんでした)title: 商品タイトル(英語とインドネシア語が混ざっていた)label_group: ラベルグループID(これが同じものが同一商品とみなされる)
評価指標
F1-score- 予測対象は、対象商品と同一の全ての商品の投稿ID(posting_id)。ただし,同一商品には必ず自分自身を含み,上限は50個。
- 各行(各商品)に対してF1-scoreを計算し、それを全体で平均したもの
以下はサブミッションファイルの例です。各クエリ商品に対して、その商品とマッチする商品の投稿ID全てをスペース区切りのリストで与えます。マッチする商品には必ず自分自身を含むため、matchesの列には、クエリ商品自身の投稿IDが含まれます。以下の例では、 test_123は自分以外にマッチする商品がなく、 test_456は自分以外に test_789とマッチすることを意味します。
posting_id,matches test_123,test_123 test_456,test_456 test_789
自分の解法
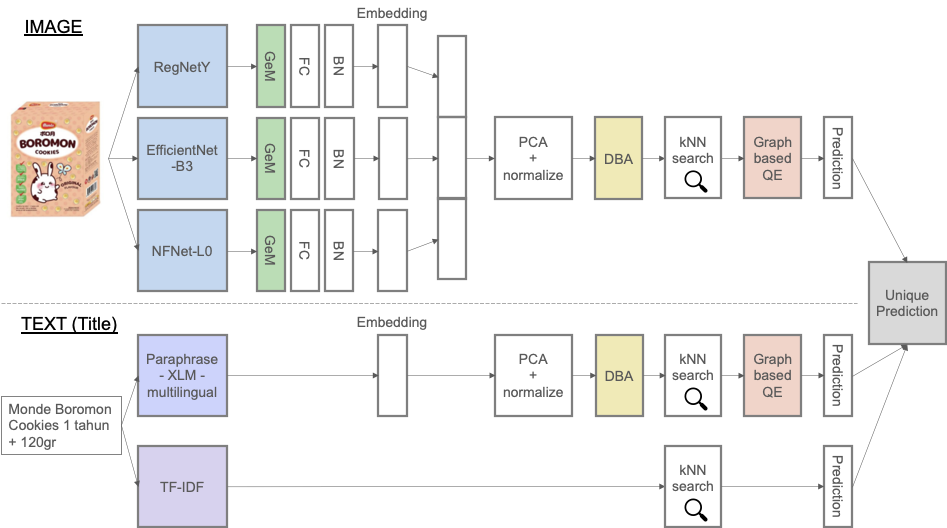
上が私の解法のパイプライン図です。大きな流れとしては、画像とテキストそれぞれでモデルを作成し、それぞれから得られた埋め込み表現を元にkNNでマッチング商品を予測し、最後に和集合をとる、というものです。上記パイプライン図におけるTF-IDF以外の4つのモデルに対しては、損失関数としてMetric learning(距離学習)で使われるArcFace loss[1]を使用しました。距離学習について簡単に説明すると、埋め込み空間において、同じクラスのものはなるべく近づけ、異なるクラスのものはなるべく遠くになるように埋め込み表現を学習する手法です。ArcFaceは、本コンペと類似の過去コンペでも有用性が示されており、本コンペでも参加者の多くがこの手法を用いていたと思われます。したがって、ArcFace自体の利用は差別化ポイントではないため、本記事では詳細は省かせていただきます。
画像モデル
以下の3つをバックボーンとして使用し、損失関数にはArcFaceを用いることで3つの埋め込み表現を得ました。それぞれのモデルから得られる埋め込み表現の次元は512次元です。
- RegNetY
- EfficientNet-B3
- NFNet-L0
様々なバックボーンを使った結果が公開ノートブックに挙げられていましたが、それらのスコア差は比較的小さく、バックボーンの選択自体は本コンペにおいて優先度は高くないと判断し、ほとんど試行錯誤はしていません。しかし、細かいスコアアップにはもちろん繋がるため、より上位を目指す上ではもう少し拘っても良かったかもしれません。余談ですが、上位陣の解法でVision Transformerの一種である Swin Transformer [2]を使っているケースもいくつか見られたので、画像コンペにおいてもすでにTransformerが威力を発揮していることが驚きでした。
テキストモデル
以下の2つをテキストのモデルとして使用しました。画像モデル同様にあまり事前学習モデルの選択には時間を掛けていません。
- Paraphrase-XLM-multilingual [3]
- TF-IDF
商品タイトルには英語とインドネシア語が混ざっていたため、多言語で事前学習された言語モデル( Paraphrase-XLM-multilingual )を使用しました。他の参加者の解法を見ると、インドネシア語で学習された IndoBERT [4]を使用しているケースも多かったようです。
また、一般的な文章と比較して、商品のタイトルは単なる単語の羅列に近いため、TF-IDFのような単語をカウントして重み付けするだけのシンプルな手法でも有効だったと考えられます。実際にdiscussionなどを見ていても、多くの参加者がTF-IDFの有用性に言及していました。
以下では、公開ノートブックやdiscussionでは触れられていなかったものの、スコアアップに効果があったものをいくつか紹介します。
GeM pooling[5]
過去に行われた画像検索コンペのGoogle Landmark Retrieval 2019における1位の解法[6]を参考に、pooling層にGeneralized-mean (GeM) pooling(パイプライン図の緑色部分)を使用しました。pooling層の出力は以下の式で得られます。
ここで、は
番目の特徴量マップであり、
です。パラメータ
は学習も可能ですが、簡単のため、論文著者らがGithubに公開しているコード[7]のデフォルト値(
)を使用しました。なお、
の場合はmax pooling、
の場合はaverage poolingに対応します。ちなみに、GeMの効果は後述するDBAやGraph-based QEと比較すると非常に小さかったです。
Database Augmentation (DBA)[8]
こちらもGoogle Landmark Retrievalの上位解法[9]を参考にしました。パイプライン図では、黄色部分になります。DBAは非常にシンプルな手法で、各商品の特徴量に対して近傍個の特徴量との重み付き和を計算し、それを元の特徴量と置き換えるものです。ここでの特徴量とは、画像とテキストのモデルから獲得した埋め込み表現をPCAによって512次元に圧縮した後の埋め込み表現となります。
ここで、は元の特徴量から
番目に近い特徴量で、
は常に自分自身の特徴量です。パラメータ
の値を大きくしすぎると、クエリと距離が遠い別の商品の特徴量も含めてしまうため、調節が必要となります。
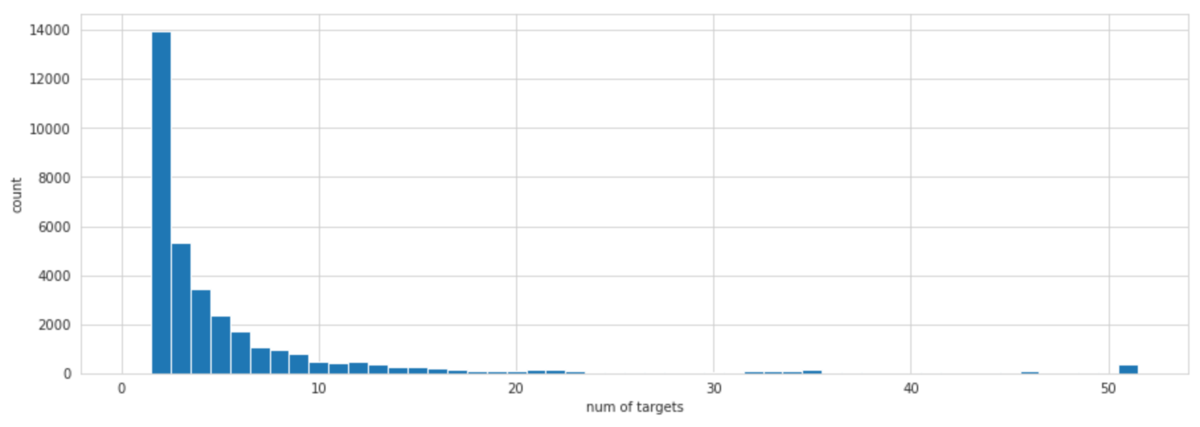
の値はいくつかのパターンで試しましたが、
の場合が最も良い結果となりました。以下の図は横軸に自分を含めたマッチング商品数をプロットしたヒストグラムですが、この図から分かるように、マッチング商品数が2個の商品が最も多いことが
で最も良い結果になった理由と考えられます。つまり、同一商品が2個の商品に対して
としてしまうと、異なる商品まで含めてしまうため、特徴量に悪影響を及ぼします。
重みに関しては、[9]を参考にして、としました。ただ、この重みの決め方はクエリと最近傍商品の類似度を考慮できておらず、似た商品であろうと似ていない商品であろうと、近傍に対して固定の重みを掛けます。そこで、重みを固定値にするのではなく、類似度(の冪乗)を使うことでよりDBAの質が上がると考えられます。実装自体は簡単なのですが、なぜか私はここで面倒臭がってしまい、結局類似度を使った重み付けは行いませんでした。しかし、コンペ終了後に上位の解法で使われているのを見ると、やはりこれを行っていた方が良かったと後悔しました。
Graph-based QE
先に紹介したDBAと同様に、過去の類似コンペの上位解法でよく使われている手法にQuery Expansion (QE)[10]があります。これは、あるクエリに対して何らかの方法で新しい別のクエリを作成し、元のクエリと合わせて2つのクエリを使って検索をする手法です。この利点として、効果的な新しいクエリを追加できれば、元のクエリだけでは検索でヒットしなかった商品もヒットさせることできるようになります。では、どのように新しいクエリを作成するかというと、よく使われる方法としては、クエリの近傍個の特徴量との平均を取るものや、類似度(のα乗)を使った重み付き平均などがあります。後者は、α-QE [5]と呼ばれ、
の時普通の平均と一致します。
私は実装を簡単にするのと、計算時間を短縮するために、よりシンプルな手法を用いました(パイプライン図のオレンジ部分)。具体的には、新しいクエリを作成する代わりに、すでに同一商品と予測されている商品群を新しいクエリとみなしました。例えば、クエリに対し予測によって以下のようなグラフが描けたとします。
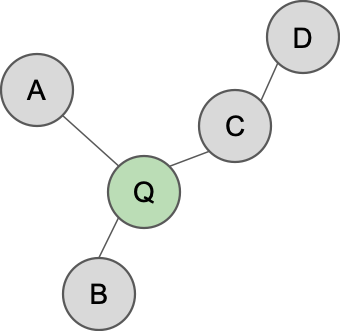
ここで、からエッジが引かれている商品(
)は
と同一商品と予測されたものです。この時、
と
の間にエッジはありませんので、もし
も
と同一商品だった場合は、
を見逃してしまいます。ですが、すでに
と同一と予測されている商品
を新しいクエリとみなすと、
も予測結果に追加することが可能となります。クエリからの近傍
個をナイーブに新しいクエリに追加するのではなく、先に類似度に対してある閾値でスクリーニングを掛け、残ったもの(同一商品と予測されたもの)のみを新しいクエリとして追加することで、False positiveをなるべく上げないようにしているのがポイントです。
また、今回の解法の中でTF-IDFを使用していますが、TF-IDFのように単語の意味を考慮できない単純な特徴量では、ちょっとした特徴量の変化でも意味的には大きく変化することもあるため、近傍の特徴量を利用することはFalse positiveを増やし、逆効果となることが考えられます。これは、DBAも同様です。したがって、TF-IDFに対しては、DBAやGraph-based QEは使用していません。
上位解法との差分
以下では、自分の解法には含まれていないものの上位解法には含まれており、さらなるスコア向上のためには重要だったと考えられるテクニックについていくつかご紹介します。
2nd stageモデル
2位、3位、5位、10位のチームが2nd stageモデルを作成していました。これは、画像やテキストの埋め込み表現から類似度を計算し、ある閾値で同一商品を予測するのではなく、類似度や距離を元にもう一段階モデルを組んで最終的な予測とするものです。具体的には、同一商品の候補となる商品ペアに対して、それらの類似度や距離などを特徴量として、LightGBMやXGBoostなどで対象ペアが同一商品かどうかを予測します。テストデータには約70000件の投稿商品が存在し、ペアの組み合わせ数が膨大であるため、いかにこの処理を高速化するかが重要だったようです。高速化には、cumlのForestInference [11]というGPUを使って推論を行うライブラリが有用で、数十倍の高速化ができるようです。
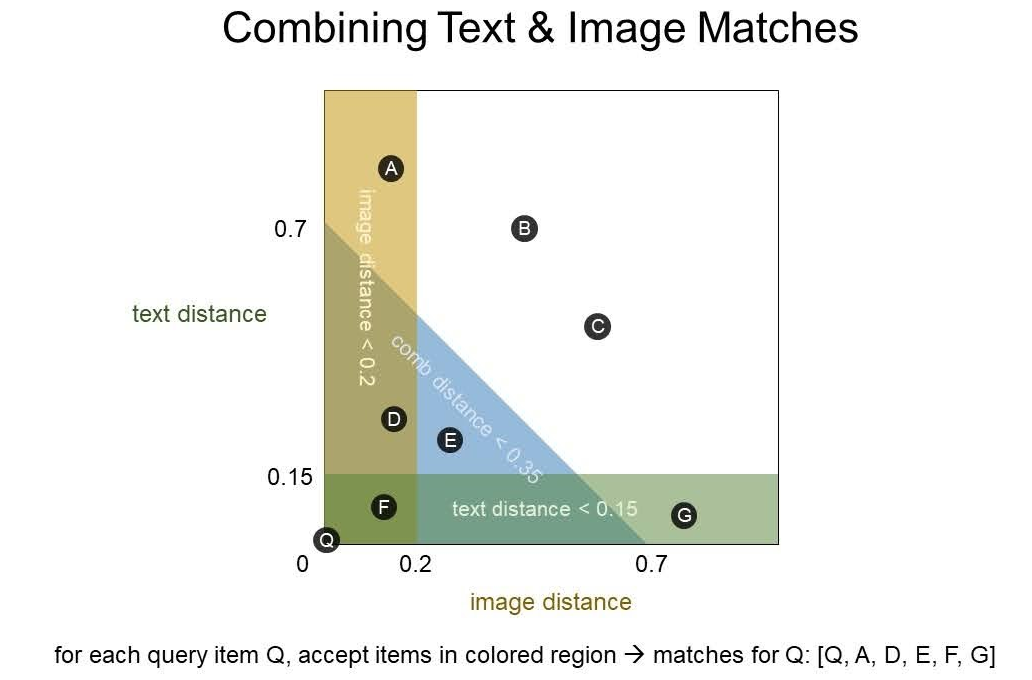
画像とテキストの予測の組み合わせ
今回のコンペでは、画像での予測結果とテキストでの予測結果をいかに上手に組み合わせるか、という点も重要だったように思います。画像が似ている商品(下図の黄色領域)とテキストが似ている商品(緑色領域)だけではなく、画像とテキストがどちらもそこそこ似ている商品(青色領域)も予測に加えることでスコアが向上したようです。下の図の例では、クエリに対して、自分自身を含む
]を予測結果とします。
類似度を用いたDBAやQE
DBAやGraph-based QEの項でも触れましたが、クエリ近傍の特徴量に対して何らかの方法で重み付けして新しい特徴量を得る際には、固定の重みではなく類似度を利用する方がやはり精度は良くなるようです。DBAやQEを使っていたチームはほぼ全て類似度を使った重み付けをしていたのではないかと思われます。このやり方自体には気付いていたので、面倒臭がらずに実装していれば良かったと後悔しています。
Kaggle初参加を振り返って
今回、Kaggleに初めて参加しましたが、2、3年ほど前からKaggleの存在自体は知っていました。ただ、業務が忙しくKaggleに割く時間がない、と自分の中で勝手に言い訳をして、長いこと参加してきませんでした。しかし、業務で用いるアプローチが、すでに自分が知っているものや過去に使ったことのあるものばかりであることに気付き、もっとアプローチの幅を広げたいという思いから、最新技術に触れることができるKaggleに参加することにしました。私は普段、テーブルデータを扱うことが多いため、画像やNLPの技術も使えるようになりたい、という思いもありました。今回Shopeeコンペを選んだのもそのためです。
序盤は、初参加でしかもソロ参加だったため、勝手が分からず、「Submission CSV Not Found」を連発し、苦労しました。ただ、参加したのがコンペ終了まで残り1ヶ月を切った頃で、すでに公開コードやディスカッションが充実していたため、取り掛かりやすく、タイミング的には良かったと思っています。一方で、他の参加者(特に上位陣)と比較すると、自分は実験の数が圧倒的に足りなかったなと思いました。より高いスコアを目指す為には、公開されているノートブックやdiscussionなどの情報を単に鵜呑みにするのではなく、問題の本質を見抜く為に自分の頭でしっかり考え、データを確認し、その上で多くの実験を繰り返すことが重要だと感じました。
実際に参加してみて思ったのは、Kaggleは世界中のデータサイエンティストが自分たちの知識や技術を惜しげもなく共有し、機械学習の知見を深めるには非常に効果的な場であるということです。今はまだ、恩恵にあずかるだけですが、いつか自分もこのコミュニティに知見を還元できるようになりたいと思いました。次回参加する際には、ぜひ金メダルを獲得したいです。
参考リンク
[1] https://arxiv.org/pdf/1801.07698.pdf
[2] https://arxiv.org/pdf/2103.14030.pdf
[3] https://arxiv.org/pdf/2004.09813.pdf
[4] https://arxiv.org/pdf/2011.00677.pdf
[5] https://arxiv.org/pdf/1711.02512.pdf
[6] https://www.kaggle.com/c/landmark-retrieval-2019/discussion/94735
[7] https://github.com/filipradenovic/cnnimageretrieval-pytorch/blob/master/cirtorch/layers/pooling.py
[8] https://arxiv.org/pdf/1610.07940.pdf
[9] https://www.kaggle.com/c/landmark-retrieval-challenge/discussion/57855
[10] https://www.robots.ox.ac.uk/~vgg/publications/papers/chum07b.pdf
[11] https://medium.com/rapids-ai/rapids-forest-inference-library-prediction-at-100-million-rows-per-second-19558890bc35
[12] https://www.kaggle.com/c/shopee-product-matching/discussion/238136