こんにちは、エクサウィザーズNLPギルド所属の神戸です。
本記事では、3月に終了しました「AI王 〜クイズAI日本一決定戦〜 第2回コンペティション」の振り返りとなります。 NLPギルドのチームで参加しまして、3位入賞という結果になりました!
要点
- コンペのタスクやルール、配布データについてなどの概要を説明しています
- コンペで3位に入賞した投稿システムの説明資料を公開しましたので、質問応答システムにご興味のある方はご参考ください
- コンペ中に複数のWebサイトからクローリング&スクレイピングして独自に作成したデータセットも公開しましたので、ご活用ください
コンペ概要
- 日本の(日本語を対象とした)質問応答研究を促進させることを目的としています。クイズ問題を題材とした質問応答データセットを用いてクイズに解答するAIを開発するコンペとなっています。
- 去年に第1回目コンペが開催され、今年が第2回目コンペとなります
- 東北大学、理化学研究所、NTTの共同プロジェクトで運営をされています。
コンペルール
ルールは大まかに以下のようなルールがありました。Wikipediaのナレッジソースなども含めた形式でDockerファイルを提出するようになっておりこの辺りはよくみるコンペとは異なっているところかと思います。
- 情報源,モデル等含めて圧縮済みで30[GB]以内、実行環境を含むDockerイメージを提出 + 実行時間 6h以内
- 評価値 = 1,000問の正答率 (配布学習データ 22,335問)
- 暫定評価:⽂字列の完全⼀致(Exact Match)で確認
- 最終評価:⼈⼿で表記の揺れなども考慮して確認
- Wikipediaを含め,⼀般公開されている, もしくは公開できるデータのみ利⽤可能
- 外部リソース(インターネット検索など)は利⽤禁止
また、第2回コンペでは,第1回のコンペと異なり選択肢を排除し,あらゆる解答がありえるという,より通常のクイズ大会に近い設定となっていました。つまり,問題として与えられるのはクイズの問題文のみとなっていました。その問題文のみから解答となる文字列を解答として返すシステムを構築する必要がありより汎用的&難易度の高い設定になっていました。
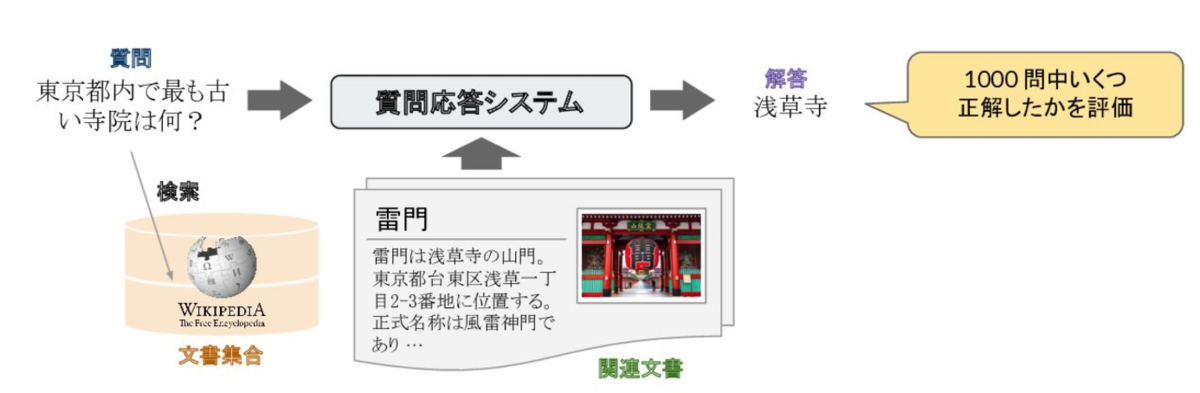
引用: 加藤拓真, 宮脇峻平, 第二回AI王最終報告会 - DPR ベースラインによる オープンドメイン質問応答の取り組み (2022) - Speaker Deck
配布データ
公式からは以下のデータが配布されています。
- 学習用データ
- 第2回コンペティション 学習用データ (22,335問)
- 開発用データ
- 第2回コンペティション 開発用データ v1.0 (1,000問)
- 評価用データ (1000問)
- 第2回コンペティションの評価用データは,コンペティション終了後に公開されるとのことです
また、学習用データのサンプルのフォーマットは以下のようになっています。
{ "qid": "AIO02-0001", "competition": "第2回AI王", "timestamp": "2021/01/29", "section": "開発データ問題", "number": 1, "original_question": "映画『ウエスト・サイド物語』に登場する2つの少年グループといえば、シャーク団と何団?", "original_answer": "ジェット団", "original_additional_info": "", "question": "映画『ウエスト・サイド物語』に登場する2つの少年グループといえば、シャーク団と何団?", "answers": [ "ジェット団" ] }
投稿システム説明と独自作成したデータセット
私たちのチームの投稿システム説明資料(最終報告会で発表したものと同じ)と独自に作成したデータセットはアップロードしていますので、こちらをご参照ください。
投稿システム説明資料 drive.google.com
独自に作成したデータセット(データセットについては説明資料の外部データをご参照ください) drive.google.com
作成したデータセットの統計は以下のようになっています。データ数としては76721となっており質問応答のデータセットとしては比較的多いデータ量になっています。 また、Elasticsearchで正例のpassageを付与できたものの数は60443となっていました。

投稿システムの簡潔なまとめは以下となります。
- Retriever-Reader構成のモデルを使用
- Retriever: 東北大BERT-Baseモデル(cl-tohoku/bert-base-japanese-whole-word-masking)
- Reader: 東北大BERT-Large(cl-tohoku/bert-large-Japanese)
- 正例のpassageをシャッフルして学習
- 学習したRetrieverのhard negativeなサンプルを学習データに追加して再学習
- 外部データの活用
- クイズの杜、みんはや、Mr Tydi、Quiz Works、語壺、Erin、Wiktionary QA、5TQなど外部データを利用
- 外部データはクローリング&スクレイピングして作成
- サイトごとにクローリング&スクレイピングするコードを実装して作成しました
また、リーダーボードスコアの遷移の以下のようになっています。
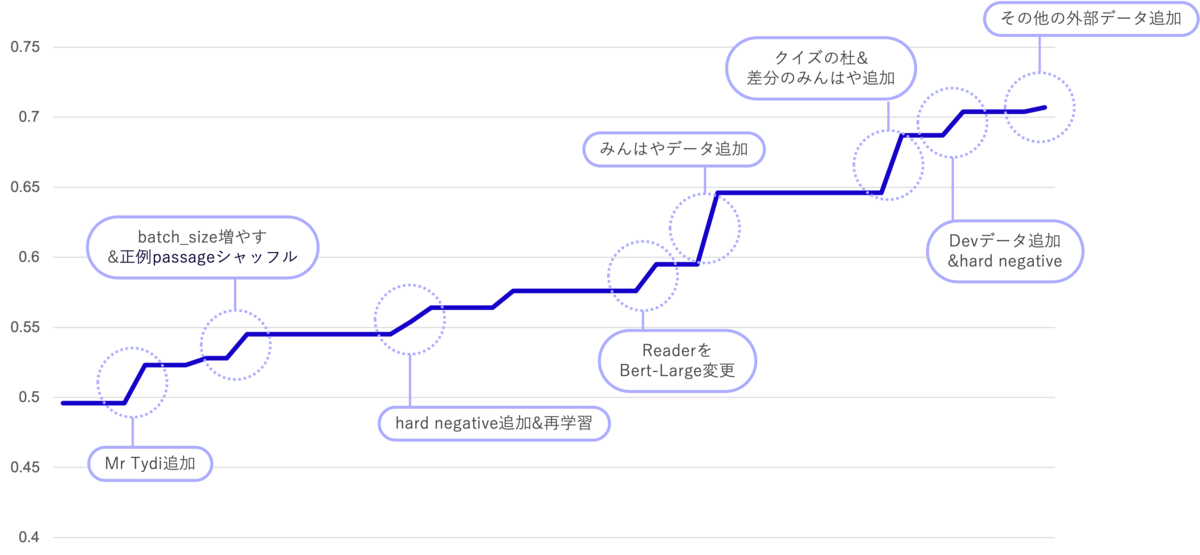
結果
最終結果は3位でした!(自動評価2位、人手評価3位) また次回コンペが開催されるとのことなので、次回コンペではより良い結果を目指したいと思います!
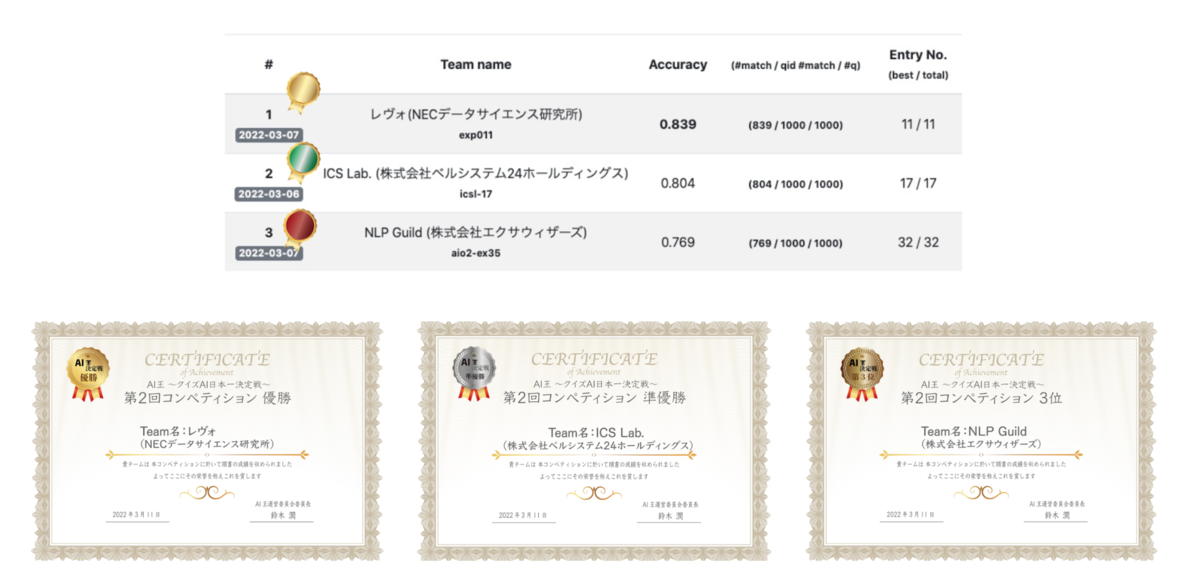
引用: AI王 〜クイズAI日本一決定戦〜 第2回コンペティション 公式サイト
コンペを振り返って
コンペに参加してみて以下のような多くの学びがありました。コンペを通じて得られた知見を今後の業務に活かしていきたいと思います。 また、引き続き今回のようなコンペに参加し外部への情報発信にも取り組んで参りたいと思います。
- Retriever-Readerの構成の質問応答タスクで、ナレッジソースから関連のあるドキュメントもとってくるところもやるのは初めてだったので学びになった
- Web上に質問応答タスクに使えそうな外部データが結構あることを知ることができたのも学びだった
- データ量はやはり重要だと再認識、反面いかに少量のデータで精度を出せるかも重要
- 1,2位のチームは外部データの利用なく精度が出ていたので、参考にしたい
- エラー分析より、BERTの文脈理解だけでは解くことができない問題を理解できた
- エラー分析については投稿システム説明資料をご参照ください
エクサウィザーズでは一緒に働く人を募集しています。中途、新卒両方採用していますので、興味のある方は是非ご応募ください!