こんにちは、エクサウィザーズで自然言語処理ギルドに所属している神戸です。(ギルド制についてはこちら)
今回、AI/機械学習を用いたデータ分析技術の国際的なコンペティションプラットフォームKaggle上で2021年8月 ~ 2021年11月まで開催されていたchaii - Hindi and Tamil Question Answeringコンペ(略: chaiiコンペ)に参加し、私を含む "tkm kh" というチームで943チーム中2位に入賞&金メダルを獲得することが出来ました。

同時に今回の金メダルの獲得で私(kambehmw)はKaggle Competitions Masterに、チームを組んでくださったtkm2261さんはKaggle Competitions Grandmaster(GM)に昇格しています。tkm2261さんは、さすがGMという実力の方でコンペ中色々なことを学ばさせていただきました。チームを組んでいただきありがとうございました!
この記事では、今回のコンペでの私たちのチームの解法について紹介させていただきたいと思います。 また、KaggleのDiscussionに既にチームの解法については共有されておりますが、こちらも必要に応じてご参照していただければと思います。 https://www.kaggle.com/c/chaii-hindi-and-tamil-question-answering/discussion/287917
- 解法の要点
- コンペのタスク概要
- 外部データの利用
- アンサンブル(XLM-R, Rembert, InfoXLM, MuRIL)
- デーヴァナーガリー数字 (०१२३४५६७८९)の後処理
- Cross Validationについて
- Public Leaderboardのスコア変化
- 順位変動 (Shake) について
- 精度に効かなかったこと
- chaiiコンペを振り返って
- 参考文献
解法の要点
chaiiコンペで精度に大きく寄与した工夫は以下の3点になります。コンペのタスク概要を説明した後、以下の3点について、それぞれ順に詳細に説明いたします。
- 外部データの利用
- アンサンブル(XLM-R, Rembert, InfoXLM, MuRIL)
- デーヴァナーガリー数字 (०१२३४५६७८९)の後処理
コンペのタスク概要
今回のコンペのタスクはいわゆるオープンドメイン質問応答タスク(Open-Domain Question Answering)であり、以下の入出力のペアが与えられているデータセットになっていました。 質問文とコンテキスト文は対応するペアのものが与えられている設定で、コンテキスト文を参照することで質問文に対応する解答を予測することが求められていました。
入力
- 質問文(Question)
- コンテキスト文(Context)
出力
- 質問に対するコンテキスト文の解答範囲(Answer Span)
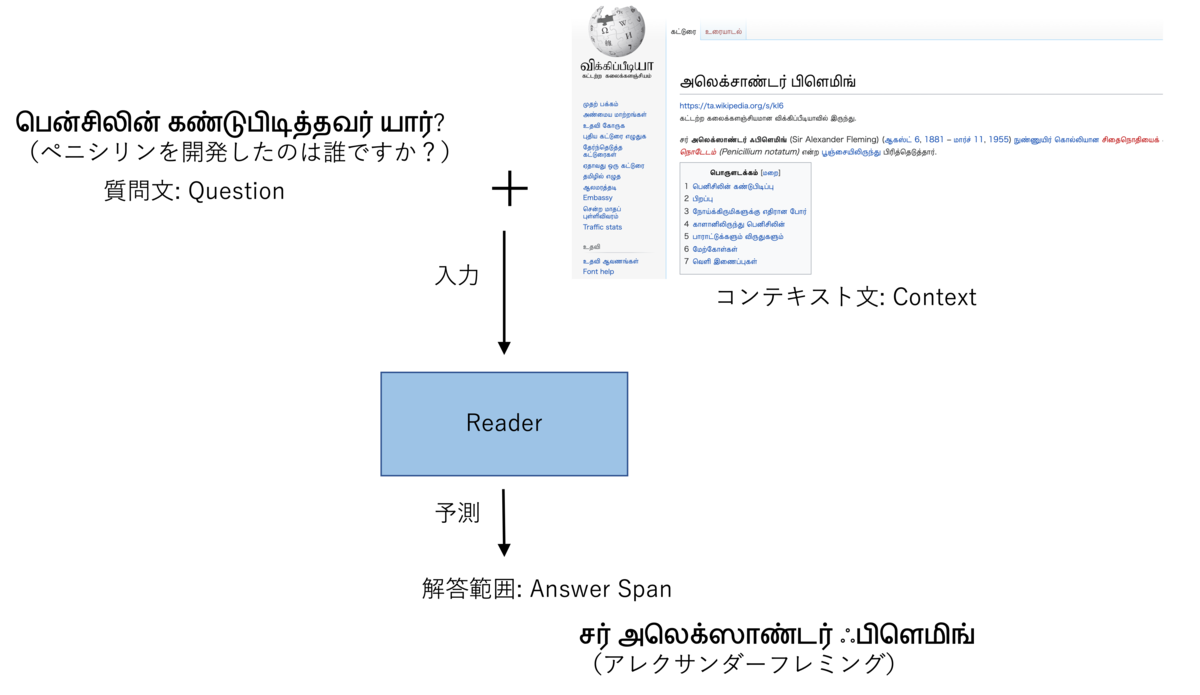
また、データセットの言語は、ヒンディー語とタミル語となっており以下のような難しさがありました。
- 英語のようなリソースが多い言語に比べて利用できる外部データ、学習済みモデルが少ない
- 読むことができない言語のため、EDAやエラー分析が大変
- Google翻訳で適宜翻訳して、EDAやエラー分析を実施した
コンテキスト文は、ヒンディー語 or タミル語のWikipedia記事であり、そのため質問もWikipediaに書かれるような一般的な知識を問うようなものになっていました。
コンペのスコア評価はword-level Jaccard scoreによって計算されました。 具体的な実装はコンペの評価ページより以下になっています。
def jaccard(str1, str2): a = set(str1.lower().split()) b = set(str2.lower().split()) c = a.intersection(b) return float(len(c)) / (len(a) + len(b) - len(c))
補足:オープンドメイン質問応答タスク
ちなみに、オープンドメイン質問応答タスクは以下の3つの枠組みのいずれかで解くことが最近主流となっています。
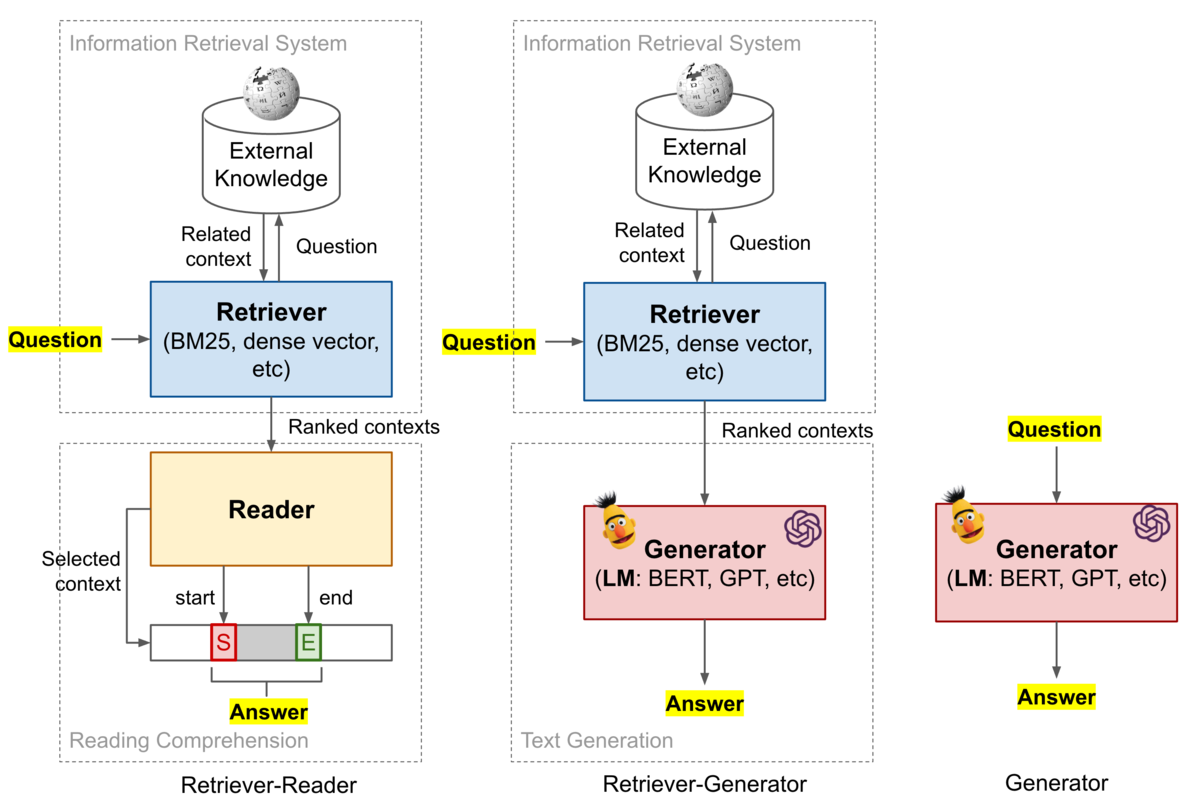
引用: https://lilianweng.github.io/lil-log/2020/10/29/open-domain-question-answering.html
今回のコンペでは解答が書かれているコンテキスト文は正解のものがあらかじめ与えられている設定でしたが、解答に関連したドキュメントも検索する必要がある場合は図のRetriverに相当したコンポーネントも実装する必要があります。(今回コンペでは、左下のReader部分のみ実装すれば良かった)
Retrieverは質問に解答するのに必要な情報をExternal Knowledge(例: Wikipedia)から抽出します。External KnowledgeがWikipediaの場合、RetrieverはBM25やDPR[1]といった手法を使用して質問に関連したドキュメントを抽出するのが最近の論文で行われることが多いです。
また、解答範囲の位置を予測するReaderではなく、質問文&コンテキスト文を入力して解答をテキスト生成的に予測するRetriever-Generator[2]の手法や、質問文のみを入力に直接解答を予測してしまうGenerator[3]の手法なども提案されています。Generatorの手法としてはT5などのパラメータを非常に多く持った大規模言語モデルが使用されており、これらのモデルにおいてはExternal Knowledgeを参照せずとも解答に必要な情報をある程度のレベルまで記憶していることが報告されています。
外部データの利用
外部データの利用として、私たちのチームは以下の2つの外部データを利用しました。
- MLQA[4]
- TyDi QA[5]に含まれる他のインドの言語を入れる(ベンガル語とテルグ語)
MLQAには下の画像のように7つの言語のデータがありますが、このうちヒンディー語(hi)のデータを一緒に学習することで精度向上しました。
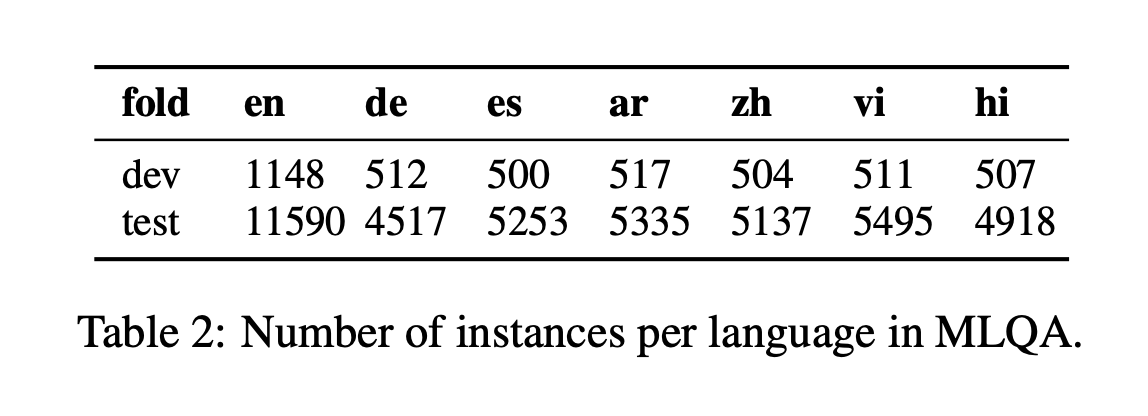
また、TyDi QAは英語以外に10種類の言語のデータがあり、このうちのベンガル語とテルグ語のデータを一緒に学習することで精度向上しました。 特にTyDi QAと学習することで、Public Leaderboardのスコアは0.787 -> 0.799に改善しました。
推測にはなりますが、TyDi QAで精度改善した理由を私たちは以下のように考えています。
- 同じインドで使用されている言語のため類似性がある
- TyDi QAのデータと質問が重複している
アンサンブル(XLM-R, Rembert, InfoXLM, MuRIL)
chaiiコンペの前にあったCommonLitコンペの上位解法から、NLPコンペでアンサンブルは重要だと考えていました。 以下が私たちのチームが使用したモデルになります。モデルは全てlargeサイズを使用しました。
- XLM-R[6] (7 models)
- RemBert[7] (3 models)
- https://huggingface.co/google/rembert
- 110言語のデータでmasked language modeling (MLM)を使用して事前学習したモデル
- 入力の埋め込み層の次元数を小さくする一方、出力の埋め込み層の次元数を大きくし効率的に事前学習するモデルになっている
- InfoXLM[8] (3 models)
- https://huggingface.co/microsoft/infoxlm-large
- 情報理論の枠組みを使った事前学習を行い、論文でXLM-Rの精度を改善したと報告しているモデル
- MuRIL[9] (2 models)
- https://huggingface.co/google/muril-large-cased
- Bertのlargeアーキテクチャを使用、インドの17言語データで事前学習されたモデル
また、アンサンブルに関連した情報は以下です。
- AlexKay/xlm-roberta-large-qa-multilingual-finedtuned-ruのモデルはロシア語の質問応答データセットでfine-tuningされたモデルなのですが、アンサンブルに寄与しました。
- モデルを上から順にアンサンブルしていくと、次のように次第にスコアが改善しました。(0.799 -> 0.816 -> 0.821 -> 0.827 -> 0.829)
- モデルごとにトークンの分割が異なるので、charレベルで予測の出力を合わせてsoftmaxで値を正規化するという操作を入れました
- シード値を変えてモデルを学習したランダムシートアンサンブルもしています
デーヴァナーガリー数字 (०१२३४५६७८९)の後処理
後処理として、選択された解答の文字列がデーヴァナーガリー数字 (०१२३४५६७८९)だけで構成されていた場合にアラビア数字 (0-9)に置き換えるという処理を入れました。 これは、年(year)が解答になっている質問に対してアノテータがアラビア数字を使ってアノテーションするように一致していたからのようです。 後処理なしのスコアが0.806で、後処理によって0.02ほどの改善をしました。
後処理の実装の詳細について知りたい方は、以下のコードをご参照ください。 https://www.kaggle.com/tkm2261/tkm-tydi-rem-info-muril-xtream-xquad
Cross Validationについて
ローカルでのCross Validationの評価についてはチームで何もせず、Public Leaderboardのスコアに対してチューニングをしていきました。ローカルで評価をしなかった理由は以下になります。
- Cross ValidationとPublic Leaderboardのスコアに全然相関がなかった
- trainデータのアノテータは1名、testデータのアノテータは3名で行なったとDataページに説明があったので、trainデータの方にはノイズがありCross Validationの信頼性が低いと推測できた
- データを目視確認すると確かにアノテーションのブレがあった。
Public Leaderboardのスコア変化
- 0.787: チームマージ
- 0.799: TyDi QA (ベンガル語とテルグ語)を用いて学習
- 0.816: RembertとInfoXLMをアンサンブル
- 0.821: より多くのXLM-R, Rembert, InfoXLMモデルをアンサンブルに追加
- 0.827: アンサンブルの重みをチューニング
- 0.829: MuRILモデルをアンサンブルに追加
- 0.831: 後処理のパラメータチューニング
順位変動 (Shake) について
今回のchaiiコンペはPublicとPrivate Leaderboardの順位変動が大きかったコンペでした。どの程度順位変動があったかをプロットしてくださったNotebookがありましたので参考までに示します。
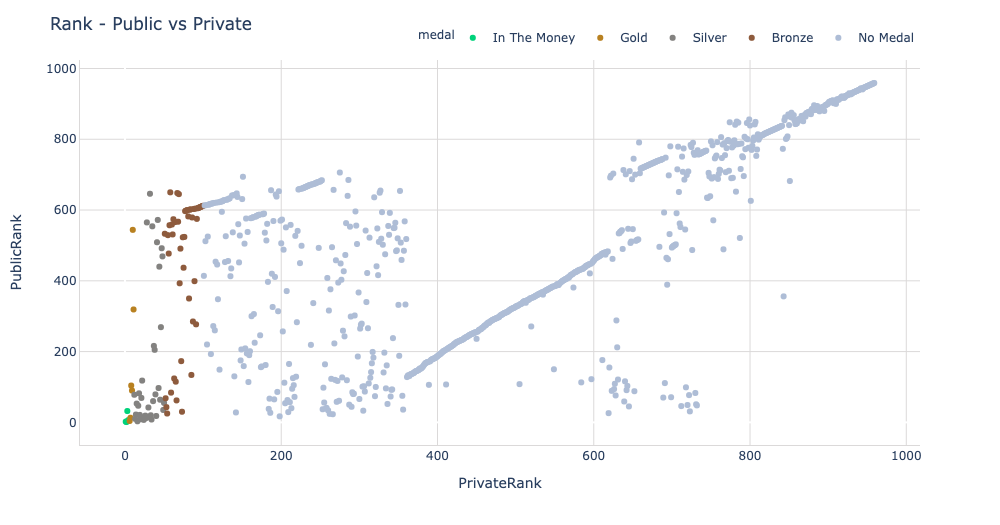
左上のPublic Leaderboard 550位くらいから、Private Leaderboardで金圏に入られていた方もいたので比較的順位変動が大きくあったコンペだったと言えるのではないでしょうか。 私たちのチームがShakeしなかった理由は以下であると個人的に考えています。
- アンサンブルで異なるモデルを使うことで多様性を上げることができた
- 外部データを活用することで、データ量を増やすことができた
- testデータの方がラベルが正確だと信じることができ、Trust LB(Leaderboard)戦略が今回のコンペでは正解だった
精度に効かなかったこと
- 様々な外部データ
- MLQAとTyDi QA以外の外部データも試しましたが、精度に効きませんでした
- 参考: https://www.kaggle.com/c/chaii-hindi-and-tamil-question-answering/discussion/287917
- 質問文をローマ字化することによるデータ拡張
- seq2seqモデルを使った擬似ラベリング
- xTune[10]モデル
- https://github.com/microsoft/unilm/tree/master/xtune
- アンサンブル候補になるレベルの精度が得られなかった
chaiiコンペを振り返って
今回のコンペは業務であまり経験のない質問応答というタスクでしたが、コンペを通じて多くの知見を得ることができました。コンペデータとは異なる言語データを含めて学習することで精度改善が見られたので、日本語についても言語的に近い他言語のデータを活用することで精度改善に役立つのではと思いました。また、RemBertやInfoXLMといった今まで試したことがなかったマルチリンガルモデルも精度的に役立つことがわかりました。コンペを通じて得られた知見を今後の業務に活かしていきたいと思います。
今回のコンペでKaggle Competitions Masterになることはできましたが、引き続き技術力を高めていくことでエクサウィザーズのビジネスにより一層貢献することを目指していきたいと思います。
エクサウィザーズでは一緒に働く人を募集しています。中途、新卒両方採用していますので、興味のある方は是非ご応募ください! hrmos.co event.exawizards.com
参考文献
- [1] Vladimir Karpukhin et al. “Dense passage retrieval for open-domain question answering.”. EMNLP 2020.
- [2] Gautier Izacard & Edouard Grave. “Leveraging passage retrieval with generative models for open domain question answering.” arXiv:2007.01282 (2020).
- [3] Adam Roberts, et al. “How Much Knowledge Can You Pack Into the Parameters of a Language Model?” EMNLP 2020.
- [4] "MLQA: Evaluating Cross-lingual Extractive Question Answering" arXiv:1910.07475 (2019).
- [5] "TyDi QA: A Benchmark for Information-Seeking Question Answering in Typologically Diverse Languages"
- [6] "Unsupervised Cross-lingual Representation Learning at Scale"
- [7] "Rethinking Embedding Coupling in Pre-trained Language Models"
- [8] "InfoXLM: An Information-Theoretic Framework for Cross-Lingual Language Model Pre-Training"
- [9] "MuRIL: Multilingual Representations for Indian Languages"
- [10] "Consistency Regularization for Cross-Lingual Fine-Tuning"